
Das eigene KI-Modell programmieren: So geht's mit Swift
Wie funktioniert eigentlich eine KI? Wir erklären die Grundlagen auf dem Mac und zeigen, wie man ein neuronales Netzwerk erzeugt und trainiert.

- Jürgen Schuck
Künstliche Intelligenz basiert auf der Idee, menschliches Denken zu formalisieren und maschinell auszuführen. Die Grundlagen stammen aus verschiedenen Wissensgebieten und entstanden teilweise schon vor einigen hundert Jahren. Den Begriff prägte der Programmierer John McCarthy auf einem Workshop, der sich unter anderem mit der maschinellen Simulation neuronaler Netzwerke befasste. Sie entstanden aus einer Kombination von Schwellwertelementen – den Neuronen – die zuvor bereits der Kybernetiker Warren McCulloch und der Logiker Walter Pitts als abstrakte Modelle menschlicher Neuronen in die Informatik eingeführt hatten.
Grundprinzipien selbst entwickelter neuronaler Netzwerke
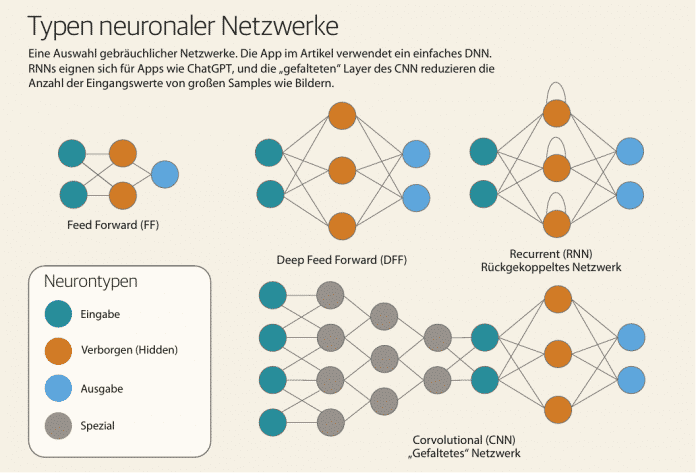
Langsame Rechner und eine mühsame manuelle Methode zum Anlernen neuronaler Netzwerke ließen das Forschungsgebiet jedoch stagnieren. Das Anlernproblem beseitigten 1986 David Rumelhart und seine Kollegen mit ihrem Back-Propagation-Algorithmus, der maschinelles Lernen auf verblüffend einfache Weise ermöglicht. Richtig Fahrt nahm das Thema aber erst um 2010 auf, als die KI-Community die Leistungsfähigkeit moderner Grafikchips für ihre Zwecke entdeckte. Neue und leistungsfähigere Typen neuronaler Netzwerke lösen sich seitdem in immer schnellerer Folge ab. Den aktuellen Höhepunkt bilden die sogenannten Transformer, ein generatives neuronales Netzwerk und der State of the Art, das beispielsweise auch ChatGPT zugrunde liegt. Das Asimov Institute hat 2016 den Versuch unternommen, eine vollständige Übersicht der seinerzeit diskutierten Netzwerktypen zu erstellen, "mostly complete", wie sie selbst sagten, und dazu ein anschauliches Poster veröffentlicht.
- KI-Apps verwenden fast ausschließlich neuronale Netzwerke.
- Mit wenig Code lässt sich bereits ein einfaches Netzwerk zur Handschrifterkennung programmieren.
- Neuronale Netzwerke müssen trainiert werden, das geschieht im vorgestellten Beispiel mit gescannten Ziffern.

Mit einigem Abstand betrachtet, arbeiten fast alle Typen neuronaler Netzwerke nach dem gleichen Prinzip, das zwei Betriebsarten unterscheidet: das Anwenden des Netzwerks auf einen Eingangswert (Prediction) und das Anlernen (Training). Bei der Prediction liefert das Netzwerk einen Wert für die Wahrscheinlichkeit, mit der das Ergebnis (Result) mit einem erwarteten Wert (Target) übereinstimmt. Beim Training vergleicht das Netzwerk die Werte von Predictions mit den entsprechenden Targets und justiert auf Basis der Differenzen seine interne Konfiguration.
Immer mehr Wissen. Das digitale Abo für IT und Technik.

Ausprobiert: Fritzbox als NAS-Ersatz verwenden
Bastel-Projekt: Elektroniklabor für den Küchentisch
Linux-Umstieg: Software unter Linux installieren
Mini-PC-Barebone für AMD Ryzen 7000/8000G im Test
BMW iX2 im Test: Elektroauto mit hohem Reifegrad
Elektroauto Fiat 600e im Test: Außen Retro, innen Zukunft?
Immer mehr Wissen. Das digitale Abo für IT und Technik.
Ausprobiert: Fritzbox als NAS-Ersatz verwenden
Bastel-Projekt: Elektroniklabor für den Küchentisch
Linux-Umstieg: Software unter Linux installieren
Mini-PC-Barebone für AMD Ryzen 7000/8000G im Test
BMW iX2 im Test: Elektroauto mit hohem Reifegrad